In my previous blog post, I had some comments on the statistical analysis present in some covid-19 studies. It is easy to criticize, but can I do better? Let’s find out what the data tells us about the fatality of SARS-coV-2.
Data by itself tells us nothing
Well, almost nothing – remember that we are trying to find something that should be more generally true than just for the individual data points that we have. For this we need a model, a mathematical description of the process that created the data points including the unknown parameters (in this case, the IFR) that we want to discover. It’s important to remember that such a model typically has a number of very strong assumptions, none of which are fully satisfied in real life. Some of these are simplifications, like omitting certain un-modelable complexities. Others are of a more systematic nature, such as not having access to truly random samples. It is important to remember that the conclusions reached within the model may therefore not apply to real life. This is true for any scientific study of this type. Even if the model holds exactly, there is usually some uncertainty “built in”. As shown in my previous post, scientists often don’t correctly deal with this built-in uncertainty.
Deciding on the model in advance
By tailoring a model to the data, one can strongly influence the results it shows. To avoid suspicions of this happening, and to avoid it happening inadvertently, one must always decide on the model before looking at the data. I have in fact seen some of the studies I’ll be getting data from (see previous blog post). But I have not done any statististical analysis that looks at how age/sex affects the IFR. I will use this blog post to set a fixed methodology before I look further.
Garbage in, garbage out
No matter how good you are at statistics, your conclusions can only be as good as your data. I will therefore limit myself to studies of a certain type and quality. In particular, I will only look at antibody studies in Western countries that
- try to get a random sample of the whole population.
- do assay validation for their tests.
- come from countries not counting “suspected” covid-19 deaths like “confirmed” ones.
- have age/sex statistics of the sample. I need to be able to find covid-19 death statistics as well as age statistics for the total population being sampled.
As I only have so much time, I will not look for studies not covered by the two meta-analyses in the previous blog post.
The model
I have underlined some key assumptions to show how many there are.
I start by binning ages into 10 year brackets, i.e. 0-10, 11-20, and so on, with a bin for each sex. I will label these by 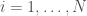
![IFR[i]](https://s0.wp.com/latex.php?latex=IFR%5Bi%5D&bg=ffffff&fg=444444&s=0&c=20201002)
In each study, the samples are assumed to come from some large total population (e.g. “people living in NYC”). I assume that within each age/sex bracket, the people sampled are random sample with respect to SARS-coV-2 infections. This is obviously not exactly true (for example, we can’t sample people who have already died), but seems like a reasonable approximation.
For each study, I split the total population into 
I assume that in each age bracket, the participants in a study randomly either have antibodies or do not at the rate in the total population. In each case, they test positive based on the sensitivity and specificity of the test, which does not vary by age/sex. The positive rate for each subpopulation (i.e. true and false positive rates) is a random variable, about which we obtain information from the assay validation.
In each age/sex category 
If age/sex data is not binned the same way as here, I will either try to increase the number of bins, or treat “20 people aged 20-40” as “10 people aged 10-20 and 10 people aged 30-40”. If a study uses intervals that are off by one from mine, I will pretend they are the same. If I don’t see a way to salvage things, or think that combinations aren’t sensible, I will exclude the study and make a note of having done so.
I will use the deaths counted by the end of the time of data collection of the study. This may miss some deaths. As it takes some time to develop antibodies we also miss some infections.
Priors
For each test, the priors for the true positive and false positive rates are uniform random variables over [0,1].
Likewise, the priors for the proportion of people who have antibodies are uniform random variables over [0,1].
IFR priors are uniform within each age/sex group over [0, upper limit of age group/100].
Things I might change
I might approximate some binomial distributions by normal ones. I might change the number of age bins if having too many becomes computationally intractable. I might use different priors for the IFR and/or proportions of antibodes, as it doesn’t really make sense to assume these are completely independent random variables accross age/sex.
Request for comments
It would be great to have collaborators on something like this. I could imagine publishing this in a journal with all authors listed alphabetically.
